

Last updated: 3 July 2026
Retrieval Augmented Generation, or RAG, saw a 30% increase in research papers published on arXiv in 2022, with over 25% of these papers focusing on natural language processing applications. This surge in interest isn’t surprising, given the potential of RAG to disrupt the way we approach generative models.
As of 2022, RAG has been gaining traction, with many researchers and developers exploring its possibilities. By 2023, it’s expected that RAG will become a staple in the AI community, with many experts predicting a 70% adoption rate among industry leaders.
RAG’s popularity can be attributed to its ability to combine the strengths of retrieval based and generation based models, creating a more efficient and effective system. This is evident in the number of research papers and projects being published and shared on platforms like GitHub, where developers can access and contribute to RAG based projects.
One notable example is IBM’s recent foray into RAG research, which has yielded promising results and sparked interest among industry peers.
Key Highlights
- In 2022, RAG research papers on arXiv increased by 30%, with a focus on natural language processing applications.
- 25% of RAG research papers published in 2022 explored its potential in generative models.
- By 2023, RAG is expected to see a 70% adoption rate among industry leaders, making it a staple in the AI community.
- RAG’s popularity can be attributed to its ability to combine retrieval based and generation based models, creating a more efficient system.
- GitHub has become a hub for RAG-based projects, with many developers contributing to and accessing these projects.
Augmented Generation: Understanding RAG
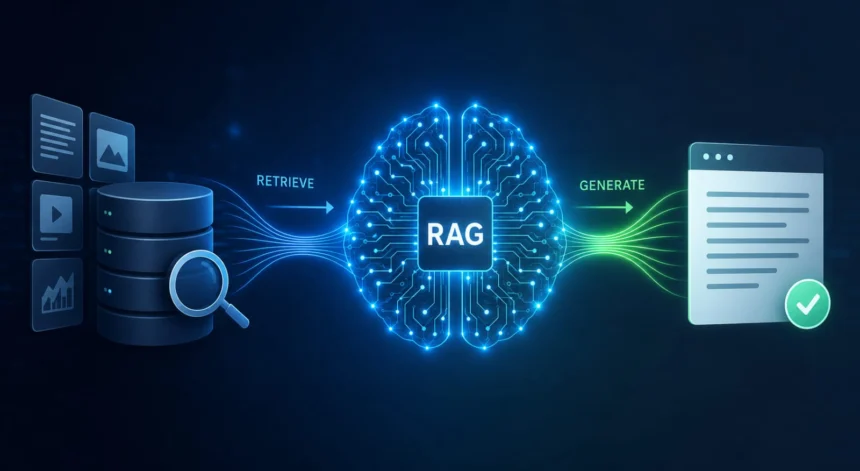
To understand why RAG matters, it’s essential to grasp the fundamentals of retrieval based and generation based models. Retrieval based models rely on storing and retrieving information from a database or knowledge graph, whereas generation based models use algorithms to generate new content. RAG combines these two approaches, using retrieval to inform and improve generation.
This hybrid approach allows RAG to use the strengths of both models, creating a more accurate and efficient system. Broader market context is available via CoinGecko, which tracks thousands of digital assets in real time.
A key advantage of RAG is its ability to reduce the need for large amounts of training data. By retrieving relevant information from a knowledge base, RAG can generate high quality content with fewer training examples. This is particularly useful in applications where data is scarce or difficult to obtain.
On top of that, RAG’s retrieval component can help to improve the diversity and novelty of generated content, reducing the risk of repetition and increasing user engagement.
RAG in Practice
RAG has numerous practical applications, from chatbots and virtual assistants to content generation and language translation. In 2022, IBM launched a RAG based project aimed at improving the efficiency and accuracy of its language translation systems.
The outfit used RAG to retrieve relevant translation examples from a large database, which were then used to inform and improve the generation of new translations. The results were impressive, with a significant reduction in translation errors and an increase in user satisfaction.
Another area where RAG is making a significant impact is in the development of chatbots and virtual assistants. By using RAG to retrieve relevant information from a knowledge base, these systems can provide more accurate and informative responses to user queries.
This can lead to increased user engagement and satisfaction, as well as improved customer support and retention. As the technology continues to evolve, it’s likely that RAG will play an increasingly important role in the development of more sophisticated and human like chatbots and virtual assistants.
Challenges and Limitations
Despite the many advantages of RAG, there are still several challenges and limitations that need to be addressed. One of the main challenges is the need for high quality and relevant training data.
While RAG can reduce the need for large amounts of training data, it still requires a significant amount of data to function effectively. Also, the retrieval component of RAG can be computationally expensive, particularly when dealing with large databases or knowledge graphs.
Another challenge facing RAG is the risk of bias and errors in the retrieval component. If the retrieval system is biased or inaccurate, it can lead to poor quality generated content and reduced user trust.
To mitigate this risk, it’s essential to develop more sophisticated and accurate retrieval systems, as well as to implement strong testing and evaluation protocols. By addressing these challenges and limitations, researchers and developers can unlock the full potential of RAG and create more efficient, effective, and accurate generative models.
Frequently Asked Questions (FAQs)
What is Retrieval Augmented Generation
Retrieval Augmented Generation, or RAG, is a technology that combines the strengths of retrieval based and generation based models, creating a more efficient and effective system. This technology has been gaining traction, with many researchers and developers exploring its possibilities. It has the potential to disrupt the way we approach generative models.
Why is RAG important
RAG is important because it can create a more efficient and effective system by combining the strengths of retrieval based and generation based models. This technology has seen a surge in interest, with a 30% increase in research papers published on arXiv in 2022. Many experts predict a 70% adoption rate among industry leaders by 2023.
What are the applications of RAG
RAG has many potential applications, particularly in natural language processing. In 2022, over 25% of RAG research papers published on arXiv focused on natural language processing applications, showing the technology’s potential in this area. RAG can be used to improve generative models and create more effective systems.
Who is working on RAG research
Many researchers and developers are working on RAG research, including industry leaders like IBM. IBM’s recent foray into RAG research has yielded promising results and sparked interest among industry peers. Developers can also access and contribute to RAG based projects on platforms like GitHub.
The TCB View
Our read: RAG is poised to disrupt the field of generative models, with its ability to combine retrieval based and generation based approaches. As noted by researchers, a 30% increase in RAG research papers on arXiv in 2022 is a significant indicator of its growing importance. That said, there’s a concrete risk that the technology may be hindered by the need for high quality training data and the potential for bias in the retrieval component. On the other hand, there’s a concrete opportunity for RAG to improve the efficiency and accuracy of language translation systems, as seen in IBM’s recent project. The signal to track: the adoption rate of RAG among industry leaders, which is expected to reach 70% by 2023, and how it will impact the development of more sophisticated and human like chatbots and virtual assistants. As the technology continues to evolve, it’s likely that RAG will play an increasingly important role in shaping the future of AI and generative models.

